I used to like monolithic software design. I build code that was using in-memory databases and can sustain pretty heavy load. In one project that I was a R&D manager for a small company: we ended up building very smart architecture. On receiving a new socket, this socket, was forwarded to one of the application threads. Each application thread was able to handle up to a thousand of sockets using the socket polling mechanism. On each client request, each application thread was working with in-memory database to handle user request and response was queued in the socket structure and was send when the socket was ready for writing (using the polling). We worked with non-blocking sockets and were able to sustain pretty heavy load a that time.
Today, I am going to talk about another approach that can drastically improve the above architecture. It was implemented by other company – LMAX – London Forex Multi-Asset eXchange. They are getting few million transactions per second (TPS) using special architecture.
This is not very strict monolithic design because they allow high availability, but still very monolithic 😉
Some of their architecture decisions were new for me, so I decided to blog about their architecture. You are welcome to send your comments bellow to open a discussion.
Some facts:
- LMAX exchange is opened to end customers, meaning end customers connect to LMAX directly and brokers do not aggregate user commands (buy/sell requests).
- As a result, big number of concurrent users.
- Achieved high throughput and low latency.
- Tried implementation solutions and found not sutable: big Oracle DB, J2EE, SEDA architecture, Actor architecture.
- “Queues are actually completely wrong data structure for doing messaging between 2 different components.”
- LMAX using java code!
Some LMAC implementation principles:
- “Mechanical Sympathy”.
- Write CPU cache friendly code.
- Keep the application data in RAM memory.
- Data is fetched from DRAM to L3 cache by 64 bytes (cache line size).
- Using 10GB network cards with userspace networking.
- Regular disks are better for Read/Write data sequential access.
- SSD dicks are better for Random Access.
- Model code – special attention to class design.
- Single responsibility principle: one class, one thing.
- Use Atomic instructions (no kernel switch, no regular mutex).
- Redo collection classes to be more cache friendly – improve cache locality.
- Controlled garbage collection.
- Using circle memory / memory ring / circle buffer as a model for message queue.
- Business login code in one thread.
- Use automatic tests.
- Take snapshot of the memory.
- Store all requests on storage to be able to reply all requests.
CPU and memory friendly code.
CPU is fetching data from memory using 64 bytes cache line. Keep your variables on the same cache line to improve performance.
Using Atomic instructions
In case you use mutexes, your code performs call request to Kernel to actually guard your operation. Think of it as of a crossroad or intersection.
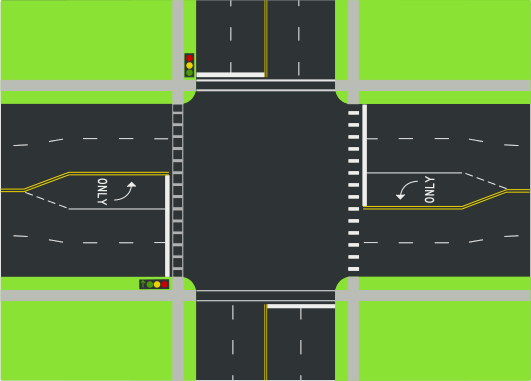
In case of Atomic instructions, it is more similar to roundabout or round crossroad. No Kernel switch is required here.
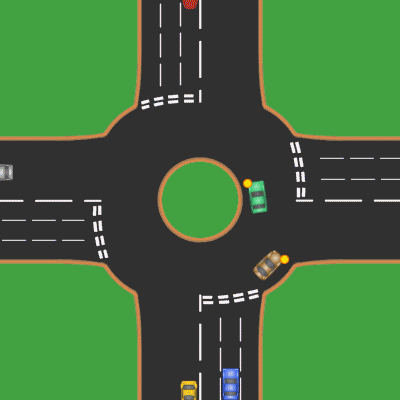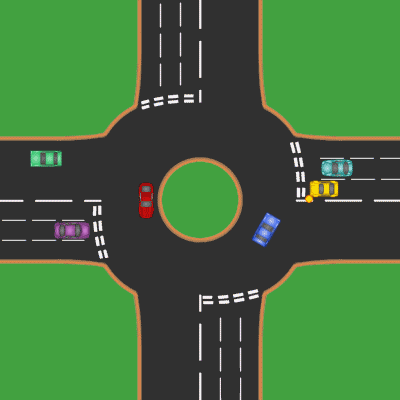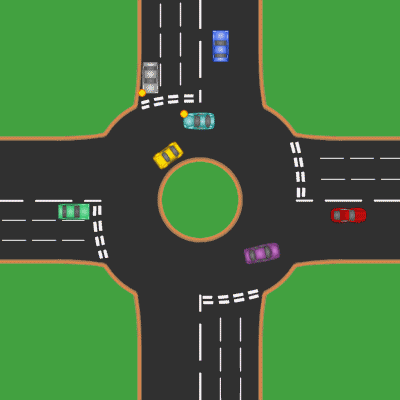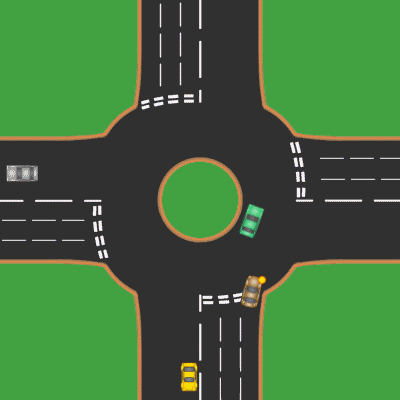
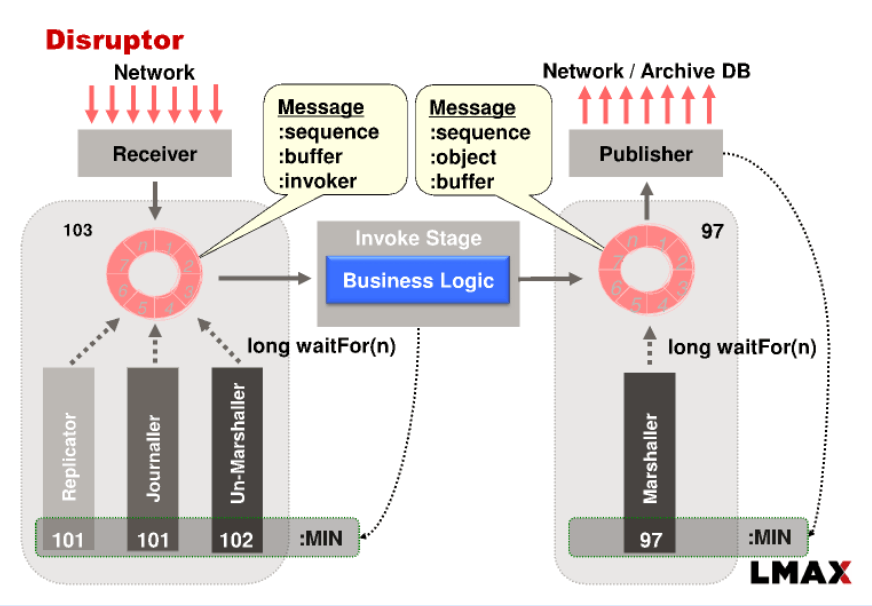
High Availability
Upon receiving new user request, it is unpacked, a sequential ID is added to it and it is pushed to other nodes using IP multi-casting. Probably using UDP packets to notify other nodes. One of the servers is a main master module running business login. When the server is down, other node becomes a Master.